데이터 OOOOO으로 찾아낼 수 있습니다. 귀사의 데이터가 병든 ‘진짜’ 이유는...
데이터 프로파일링으로
찾아낼 수 있습니다. |
|
|
데이터 프로파일링이 제대로 되지 않으면,
그 다음 단계도 도미노처럼 무너집니다. |
|
|
데이터를 활용하는 순서는 다음과 같아요.
1️⃣ 데이터 프로파일링: 데이터에 대한 정밀 검사! 데이터 속 결측치, 이상치를 세세하게 분석해요.
2️⃣ 데이터 품질 개선
3️⃣ 데이터 마이닝: 유용한 데이터를 채굴하여, 인사이트를 발굴하는 과정입니다.
만약 1, 2번 없이 곧바로 3번, 데이터 마이닝으로 들어간다면?
👉 잘못된 데이터로 인해 인사이트가 아닌데도 인사이트로 착각하게 돼요.
|
|
|
1️⃣ 결국 데이터 프로파일링을 통해 데이터의 구조, 문제를 정확하게 이해한 후
2️⃣ 데이터의 품질을 개선해야만
3️⃣ 데이터 마이닝에서 나오는 인사이트도 신뢰할 수 있어요!
이 외에 데이터 프로파일링이 중요한 이유가 3가지나 더 있습니다!
1) 데이터 거버넌스
데이터 거버넌스 = 조직의 데이터를 안전하게 관리하기 위한 체계
👉 데이터 프로파일링으로 데이터의 출처, 사용 패턴, 소유권 등을 파악해야 비로소 체계를 잡을 수 있어요.
2) 워크플로우 간소화
데이터 프로파일링을 진행하면 데이터의 오류가 한눈에 드러나요.
이를 사전에 걸러내고, 실제로 활용할 데이터만을 높은 품질 기준으로 삼을 수 있죠.
- 담당자님은 수동 데이터 정리 작업에 쓰던 시간을 줄이고,
- 모델 개선처럼 더 전문적인 업무에 집중할 수 있습니다.
- 조직 전체의 생산성이 자연스럽게 높아지죠!
3) 규제 대응
이렇듯 데이터를 활용하는 과정에서 나타나는 부작용들이 있죠.
전 세계적, 국가적 차원에서 이를 막기 위해 규제를 강화하고 있습니다.
데이터 프로파일링을 통해 위험 요소를 미리 예방해야 합니다!
|
|
|
데이터가 병든 ‘진짜’ 이유를 찾는 4가지 노하우 |
|
|
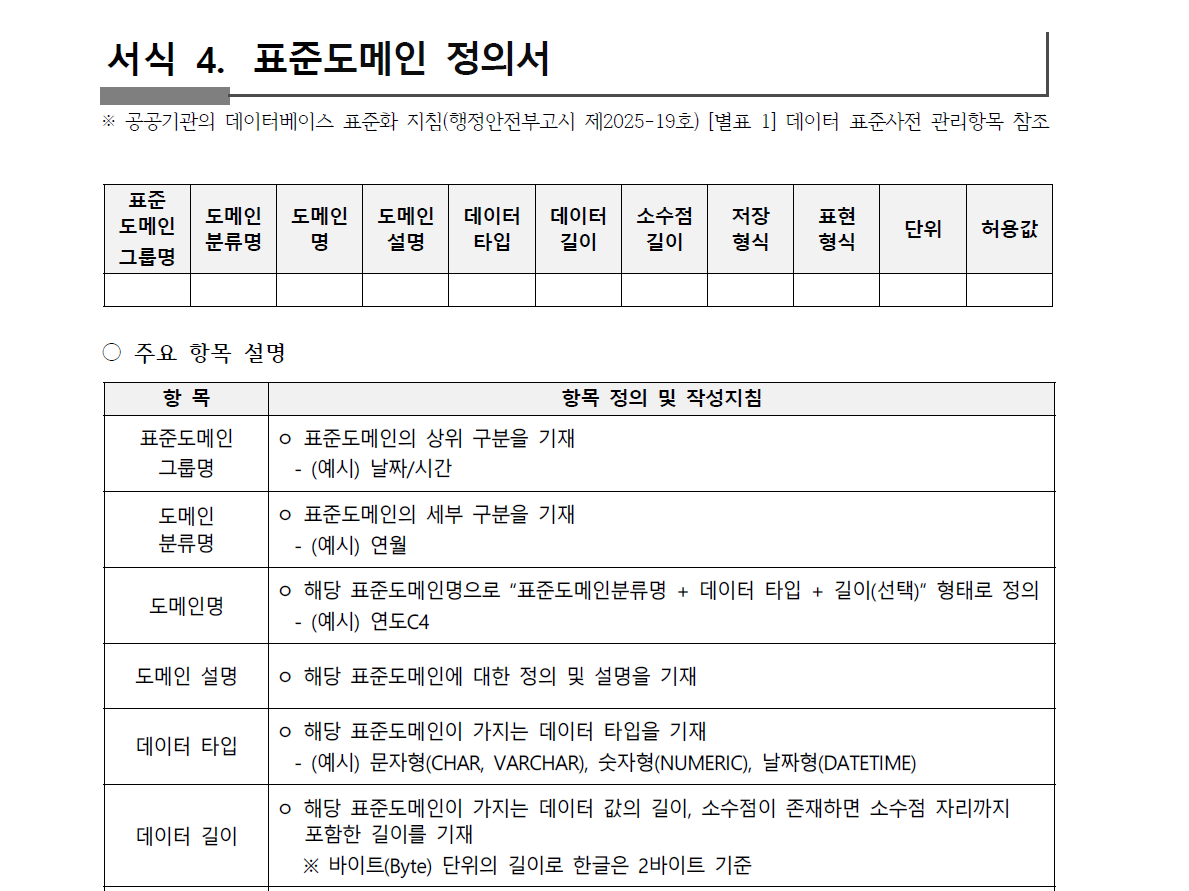
1) 정형 데이터 - 조직 맞춤형 규칙, ‘데이터 정의서’ 작성하기
데이터 프로파일링의 시작 = 데이터 정의서로 ‘규칙’을 정교하게 정의하는 것!
데이터 정의서란?
- 데이터가 가지는 의미, 규칙, 제약 조건 등을 알려주는 설명서.
- 표준도메인 정의서, 표준 코드 정의서 등 다양해요.
데이터 정의서가 중요한 이유?
정의서를 잘 작성하면, 새로운 데이터가 들어왔을 때 규칙 위반 여부를 곧바로 확인할 수 있어요.
👉 데이터팀과 비즈니스팀 간 소통 시간이 크게 줄어들어요.
⚠️ 특히 AI 기업이라면 더 중요해요!
EU AI Act, ISO/IEC 25012, ISO/IEC 42001 등에서 데이터 투명성, 추적성, 감사 가능성을 요구하기 때문.
명확한 정의서를 기반으로 한 품질 관리 체계가 있다면 모두 대비할 수 있어요.
⚠️ 공공기관 공공데이터 담당자님도 주목!
공공데이터는 공공기관별로 자체적인 데이터 정의서 작성이 요구돼요.
공공데이터 품질관리 매뉴얼이 있지만, 기준이 복잡하고 담당자마다 해석이 달라서 어려우시죠?
- 데이터클리닉 2.0은 분포, 밀도 기반의 근거를 제시해요.
- 공공데이터가 어떤 점이 문제인지, 어떤 기준으로 품질 관리를 할지 명확하게 정할 수 있어요.
페블러스 데이터 커뮤니케이션팀이 또다른 글에서 공공기관 맞춤형, 공공데이터 품질관리 방안도 정리해두었으니 확인해보시길 바랍니다!
|
|
|
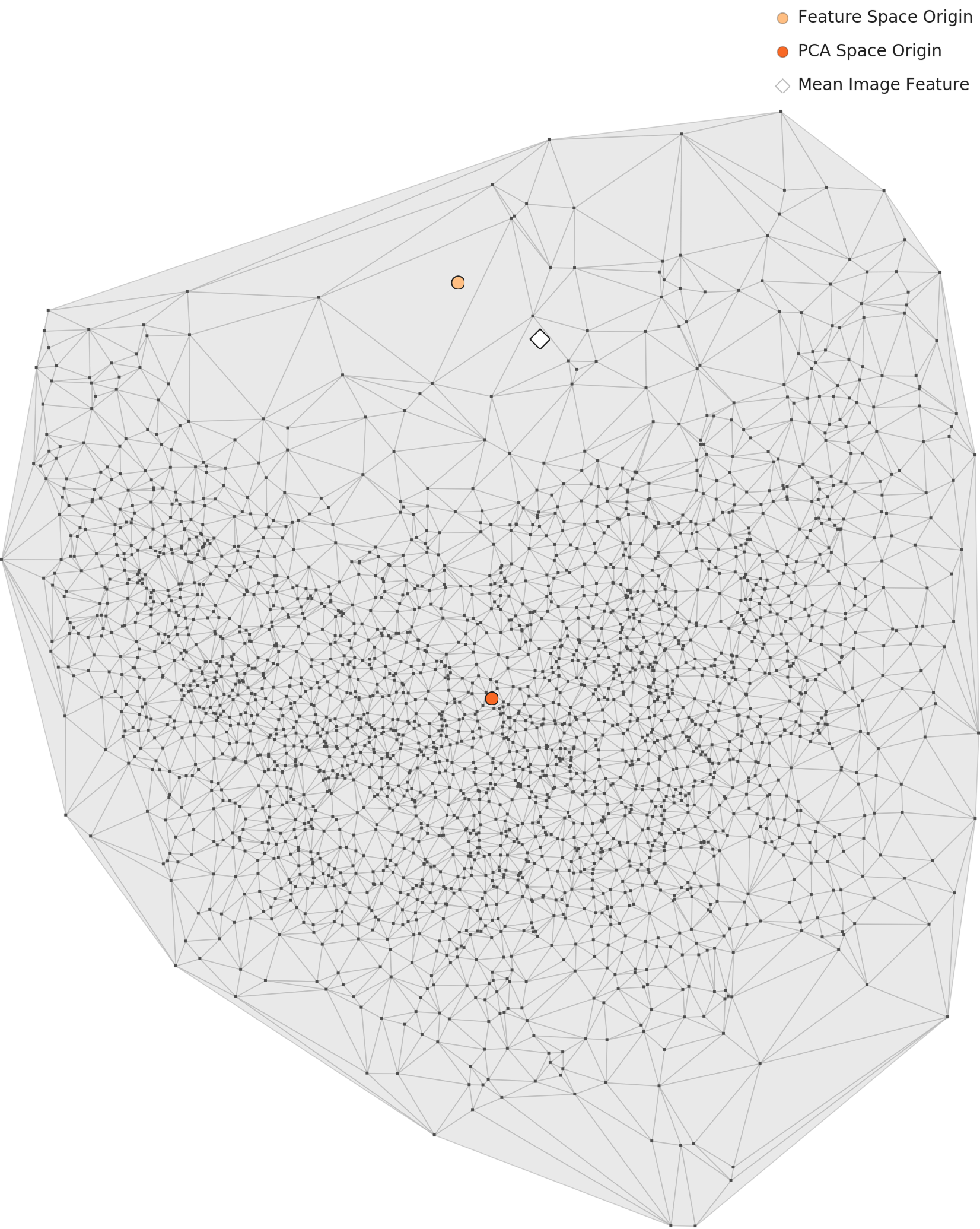
2) 비정형 데이터 - ‘데이터의 지도’를 활용해 보세요.
이미지, 오디오처럼 형태가 고정되어 있지 않은 비정형 데이터는 데이터를 분석하기에 까다롭죠.
- 명확하게 정의된 스키마나 구조가 없어서 다양성, 유사성에 대한 적절한 '선'을 명확히 찾기 어렵습니다.
- 머신러닝(ML)이나 자연어 처리(NLP)와 같은 고급 분석 기법이 필요해요.
추상적인 비정형 데이터도 구체적으로 풀어내는 기술, 데이터클리닉 2.0에 있습니다!
👉 데이터를 기하학적으로 변환하여 헷갈렸던 기준을 명확하게 만들 수 있어요!
데이터를 3차원의 지도 형태로 표현하면, 밀도, 거리, 분포 형태로 특성을 확인할 수 있어요.
유사한 데이터가 과도하게 많다면?
그래프에서 점이 한쪽으로 쏠린 형상을 보이게 됩니다.
|
|
|
3) ‘지속적으로’ 프로파일링을 해야 합니다.
데이터의 품질은 시간이 지나면서 계속 변화해요.
한 순간도 방심할 수 없는 데이터 품질...
주기적으로 데이터 프로파일링을 통해 품질을 관리해주는 것이 좋아요!
“막상 현실적으로 주기적으로 관리하는 게 어려워요."
"주기적으로 한다고 해도 꼼꼼하게 관리하는 게 힘들어요."
"문제를 발견하더라도 매번 어떻게 개선해야 할지도 또 문제에요."
많은 담당자님들의 고민이죠?
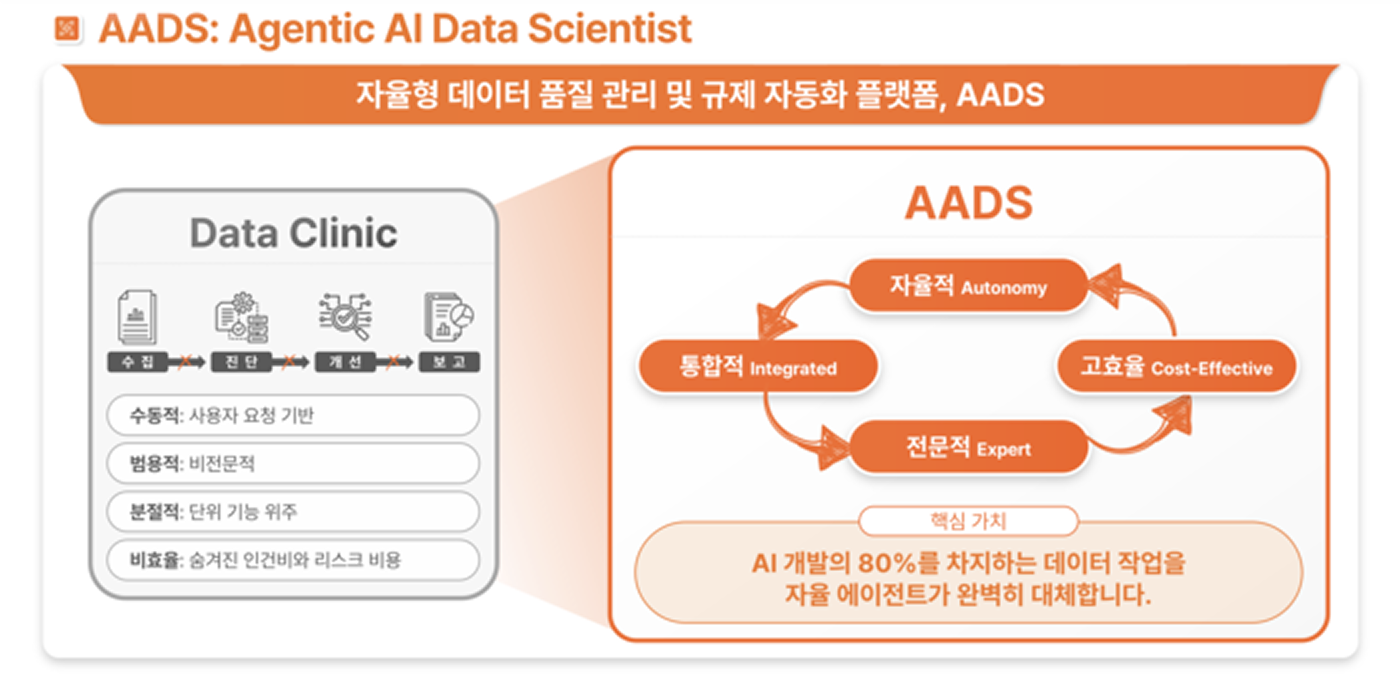
이 고민에서 시작하여 페블러스에서 탄생시킨 솔루션이 ‘데이터클리닉 2.0’이에요.
데이터클리닉 2.0?
- 자율형 AI 데이터 과학자(Agentic AI Data Scientist) 기술에 기반해요.
- AI가 자율적으로 품질 개선을 하여 매일 매일 품질 좋은 데이터를 유지해요!
- 분명 기존보다 80%는 적은 리소스를 쓰는데, 역으로 품질은 더욱 나아집니다.
|
|
|
4) 데이터 시각화를 함께 활용하면 분석력이 2배 높아집니다.
사실 단순히 숫자만 봤을 때는 품질 문제를 직관적으로 파악하기 어려워요.
- 특정 값이 한쪽에 과하게 몰려 있다거나
- 연관성이 있어야 할 필드들이 전혀 다르게 연결된 형상 등...
세부적인 문제는 잘 드러나지 않기 때문이죠.
그래서 데이터 프로파일링을 좀더 심도 있게 하고 싶다면
‘데이터 시각화 도구’를 활용해보시는 걸 권합니다.
데이터 시각화 도구, '페블로스코프'도 있습니다! 😎
3D 데이터 시각화 도구로, 데이터가 가진 구조적, 패턴적 문제를 우주의 별자리형태로 한눈에 확인할 수 있어요!
제조현장용 AI 데이터셋 샘플로 페블로스코프를 체험해 보세요.
별도의 회원 가입 없이 바로 웹에서 이용 가능합니다. |
|
|
페블러스의 도전은 멈추지 않습니다.
- 지속적인 데이터 프로파일링을 가능하게 하는 ‘자율적 AI 데이터 과학자 기술’
- 복잡한 데이터를 쉽게 파악하는 ‘데이터클리닉의 품질 진단 및 개선 기술’
- 고차원 데이터를 3차원으로 시각화하는 페블로스코프의 핵심 원리 ‘데이터이미지(IOD) 제공 기술’
🎉 페블러스의 이 모든 기술이 미국 특허로 등록되었어요!
2042년까지 해당 발명에 대한 독점적 권리를 인정받습니다.
여기서 한 걸음 더 나아가....
2026년부터 KOLAS 공인 시험기관 인정을 목표로 두고 사전 작업을 수행할 예정입니다!
👉 데이터클리닉 2.0의 데이터 품질 진단과 개선 프로세스를 ‘공식 시험 방법’으로 인정받을 수 있도록 하는 것이죠!
|
|
|
겉보기에는 충분히 건강해보이는 데이터!
그 이면에서는 데이터가 곪아가고 있을지도 모릅니다.
- 카이스트, ETRI 출신 데이터 과학자들의 노하우가 담긴 데이터클리닉 2.0으로 데이터가 병드는 진짜 이유를 끝까지 추적해드립니다.
- 유수의 공공기관, 대기업들이 데이터클리닉 2.0으로 데이터를 건강하게 만들고 있어요.
데이터클리닉 2.0(AADS) 사전 신청으로 첫 걸음을 시작해보세요! |
|
|
🚀 AI 기반 데이터 혁신, 지금 페블러스와 함께 하세요! |
|
|
페블러스는 AI와 데이터 분석을 통해 다양한 산업의 문제를 해결하고,
더 나은 의사결정을 지원합니다.
📌 페블러스에 대해 더 알고 싶거나, 협업 및 파트너십을 논의하고 싶다면
언제든지 연락 주세요!
페블러스 드림 |
|
|
|