🙅♂️ 데이터 엔지니어 A: 이 태깅이 불일치하면 품질관리 차원에서 오류입니다.
🙆♂️ 데이터 엔지니어 B: 변수를 감안해서, 이 정도면 허용 가능하지 않을까요?
이렇게 ‘오류에 대한 기준’이 사람마다 다릅니다.
⚠️ 즉 내부에서 품질 진단에 대한 '명확한 표준'을 정의해야 해요.
의사소통의 오류를 잡아야만 데이터의 오류도 잡아낼 수 있어요.
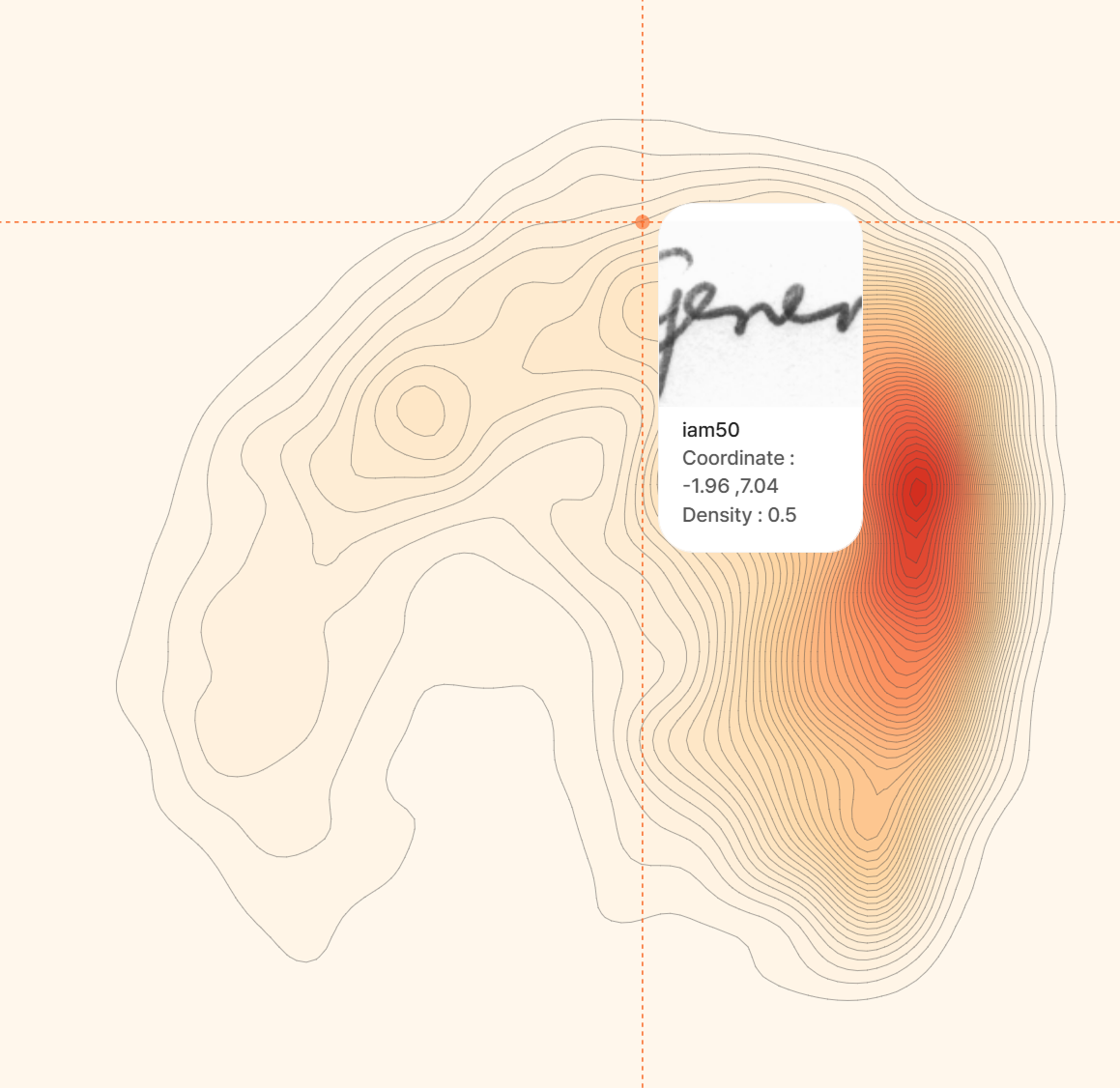
기준을 정의할 때, 각 기업의 형태마다 도움이 될만한 TIP!
AI 솔루션을 개발하는 모든 기업
기업 내부에서 기준을 수립하는 게 어렵다면, 외부 전문 기업의 전문성으로 객관적으로 데이터를 진단/개선할 수 있어요.
👉 페블러스의 데이터클리닉 2.0에서도 가능합니다! 😄
데이터 클리닉 2.0 VS 기존의 1.0 차이점은?
데이터클리닉 2.0 = 기존 데이터클리닉 1.0의 품질 진단 기술 + 'AADS(자율형 데이터 과학자 기술, Agentic AI Data Scientist)'
데이터클리닉을 사용 후, 여러분의 업무 시간의 80%가 편해지는 이유 3가지
1) 챗GPT처럼 특정 데이터에 대한 진단, 개선을 간편하게 요청해요.
데이터 과학에 특화된 LLM 기반 AI가 스스로 데이터를 자동으로 진단 및 개선해요.
2) 데이터 품질을 365일 최고의 상태로 유지해요.
데이터 품질 관리를 단 한 순간도 놓치지 않아요.
자율화된 AI로 인해 항상 최적의 상태로 유지합니다.
3) 기업에 막대한 손실을 미칠 수 있는 규제까지 자동으로 대응해요.
기업 내부 규정부터 공공기관의 품질 관리 매뉴얼, 국제 표준 등의 객관적인 기준, 표준을 학습해요.
공공기관
- ‘공공기관 기관평가’의 새로운 평가 항목에서 높은 점수를 얻을 수 있어요.
- 민간이 공공데이터를 잘 활용할 수 있도록 데이터 품질을 관리하는 공공기관이 유리해지는 것이죠.