어려워 보이지만, 방법은 분명히 있습니다! 점점 잘못되어 가는 AI 모델...
살려내는 방법은? |
|
|
사람은 ‘경험’을 통해 만들어져요.
만약 한 사람의 일생 대부분이 부정적인 경험만 가득하다면?
그 사람의 미래도 부정적으로 흘러가기 쉽습니다. 😞
인공지능은 '데이터'라는 경험을 통해 만들어져요.
잘못된 데이터를 배우면 잘못된 결과를 도출하는 AI 모델이 만들어지죠.
그런데 그럼에도 불구하고 방법은 있습니다!
부정적인 데이터를 학습했더라도, 이후 좋은 데이터를 학습한다면
더 나은 AI 모델로 변화할 수 있어요.
긍정적인 방향으로 AI 모델이 변화하는 노하우, 모두 말씀드릴게요! |
|
|
AI 데이터 구축이 필요한데,
원하는 데이터를 수집하지 못한다면? |
|
|
여러분이 특정 데이터가 필요한데, 막상 구하기가 어렵다면? 😥
보통 이 2가지 방법으로 대처합니다!
1) 크라우드 소싱: 다수에게 외주를 주어 데이터를 수집
이미지 촬영, 음성 녹음 등을 실제 사람들을 통해 맡기고 직접 데이터를 생성
2) 합성데이터 생성: 기존 실제 데이터를 토대로 현실과 유사한 가상의 데이터 생성
부족한 데이터를 채워 주는 2가지 해결책의 ‘함정’
그런데 두 방식 모두 함정이 있습니다. 물론 둘 다 좋은 방안이지만, 각각 단점이 있는 것이죠.
크라우드 소싱의 단점
- 다수의 외부 인력에게 민감 정보(의료 데이터, 금융 데이터 등)는 수집 어려움
- 불특정 참여자들의 의견과 정보를 수집하고 정리하는 데 시간, 인력 필요
합성데이터 생성의 단점
- 실제 데이터의 품질이 낮으면 합성데이터도 현실감이 떨어져요.
- 설령 실제 데이터의 품질이 높아도, 여전히 합성데이터 생성은 쉽지 않아요.
👉 고품질의 그래픽 기술, 데이터 엔지니어링 노하우를 필요하기 때문이죠!
|
|
|
1️⃣ ‘데이터 레플리카’로 안심하세요!
"데이터가 없으면 AI를 학습시킬 수 없고,
그렇다고 정보를 노출하면 보안이 위험한데… 😓"
의료, 금융, 공공기관처럼 개인정보에 민감한 기업이라면 공감하실 거예요.
그렇다면 안심하세요! 데이터 레플리카가 있습니다.
☑️ 데이터 레플리카란?
실제 데이터를 외부에 노출하지 않고,
원본의 통계적 특성과 구조를 그대로 반영하여
가상의 ‘재현 데이터’를 생성하는 기술
쉽게 말해 ‘원본 데이터와 쌍둥이지만 개인정보는 없는 합성데이터’입니다! 👬
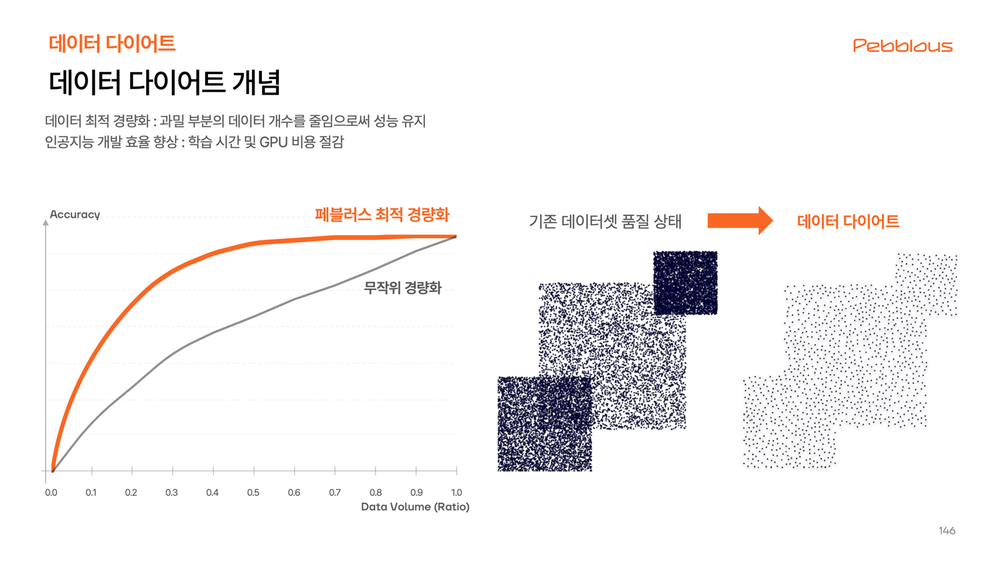
2️⃣ ‘데이터 다이어트’로 합성데이터를 만들기 좋은 환경을 마련해요.
1) 원본 데이터에서 이상치, 편향 등 학습하기 어려운 구간을 찾아내서 없애야 해요.
2) 데이터 라벨링 시 발생하는 오류도 잡아내야 합니다.
다수의 사람들이 라벨링을 한다면?
☑️ 참여자마다 이상치, 편향을 잡아내는 기준이 조금씩 달라질 수 있어요.
☑️ 참여자의 피로도가 쌓이면 품질이 흔들릴 수 있어요.
불완전한 AI가 데이터 라벨링을 한다면?
☑️ 문맥, 감정 등 인간이 파악할 수 있는 맥락을 파악하기 어려워요.
결국 라벨링의 오류, 데이터 품질 저하로 이어져요. 😓
데이터클리닉은 그래서 이렇게 대비합니다!
- AI가 학습하기 어려운 구간, 편향이 심한 영역을 자동으로 찾아내는 건 물론!
- 데이터 라벨링이 일관되게 적용되었는지를 세밀하게 평가해요.
- 발견된 오류는 즉시 수정해요.
|
|
|
3️⃣ '객관적'인 국제 표준, ‘ISO/IEC 5259’를 준수해야 합니다.
‘AI 학습 데이터 구축에 있어서, 품질이 좋다’는 기준? 🤔
사실 품질에 대한 기준은 '주관적'으로 해석될 때가 많아요.
예: 우리 기업 내부에서는 품질이 좋다고 해석해도,
외부에서 보았을 때는 품질이 떨어지는 것이죠.
그래서 ‘객관적인 기준’, 국제 표준 ISO/IEC 5259을 준수해야 해요.
ISO/IEC 5259란?
외부 데이터를 수집·재사용하는 AI, 머신러닝 환경의 특수성을 반영한 새로운 품질 기준!
페블러스 데이터클리닉 2.0은
바로 이 ISO/IEC 5259 프레임워크를 그대로 적용했습니다.
데이터클리닉 2.0 사용 후, 여러분의 AI 서비스를 고객에게 소개한다면
“ISO/IEC 5259를 준수한 데이터 품질 관리 시스템”이라는 점을 강조해 보세요!
이 한 문장만으로도 AI의 품질에 있어서 경쟁력을 어필할 수 있습니다.
특히 금융, 헬스케어 기업, 공공기관처럼
데이터 품질이 비즈니스의 핵심이라면 경쟁력은 더욱 높아질 거예요!
|
|
|
공공기관에 제공하는 특별한 혜택!
11~12월까지만 제공합니다. |
|
|
“우리 기관도 하루 빨리 AI 데이터 구축해야 하는데, 인력도 예산도 부족하다... 😥"
그렇다면 '조달청 혁신제품 시범구매사업'을 통해 데이터클리닉을 이용해보세요!
조달청 혁신 제품이란?
👉 공공기관의 문제를 민간 기술로 해결할 가능성을 인정받은 제품이에요.
👉 복잡한 행정 절차는 건너 뛰세요! 빠르게 실무에 도입할 수 있어요.
- 페블러스 데이터클리닉은 조달청 혁신제품 중 유일하게 시범구매가 가능한 데이터 품질관리 솔루션!
- 시범 구매에 참여 시, 공공기관 기관평가 점수도 높아지니 일석이조 ✌️
페블러스 데이터클리닉 X 조달청 혁신제품 시범구매사업
5천만 원 상당의 페블러스 데이터클리닉을 최대 5개 공공기관이 무료 이용 가능!
신청기간: 2025년 12월 11일 목요일 18시까지 |
|
|
데이터클리닉 X 대구디지털혁신진흥원(DIP)
웨비나 개최까지 D-5! |
|
|
드디어 웨비나 개최까지 단 5일 남았어요!
20년의 노하우, 단 1시간안에 최대한 압축해서 설명드릴 수 있도록
최선을 다해 준비했답니다.
데이터 품질 혁신을 이끄는 기업 페블러스 이정원 부대표님
대구디지털혁신진흥원 김건욱 센터장님이 만나
웨비나를 통해 AI 프로덕트에 바로 적용할 수 있는 실전 노하우를 공유해요.
📅 일시: 11월 18일(화) 오후 3시~4시 온라인 (Zoom)
🎁 참여 혜택
-
끝까지 시청하신 분들께 웨비나 다시보기 영상 및 웨비나 PPT 파일 제공, 추첨 후 커피+케이크 기프티콘 제공!
-
데이터클리닉 2.0 신청하신 모든 분들께 2개월간 프로 버전(100만 원 상당) 무료 이용 혜택 제공
-
데이터클리닉 2.0 신청자 중 추첨 10팀께 이정원 부대표님이 1:1 컨설팅 진행 (1시간 100만 원 상당)
단 10석밖에 남지 않았어요! |
|
|
🚀 AI 기반 데이터 혁신, 지금 페블러스와 함께 하세요! |
|
|
페블러스는 AI와 데이터 분석을 통해 다양한 산업의 문제를 해결하고,
더 나은 의사결정을 지원합니다.
📌 페블러스에 대해 더 알고 싶거나, 협업 및 파트너십을 논의하고 싶다면
언제든지 연락 주세요!
페블러스 드림 |
|
|
|